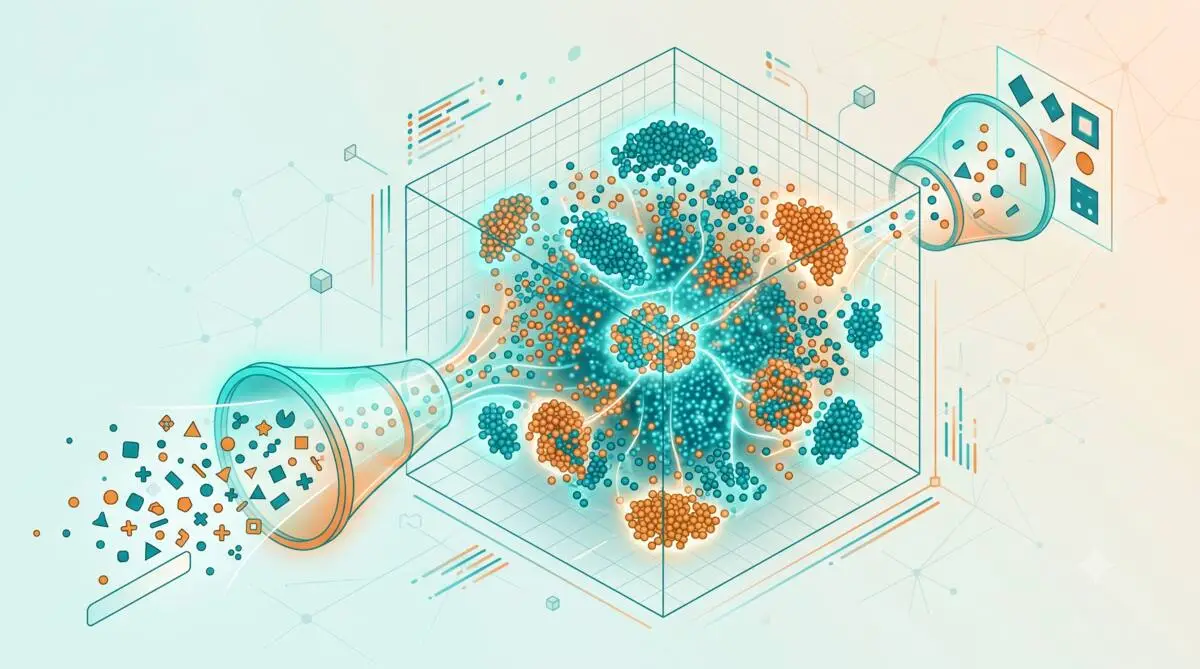
L'espace latent est une représentation vectorielle interne, compressée et de dimension réduite, où les données similaires sont proches les unes des autres.
📖 Définition
L'espace latent (latent space) est un espace vectoriel de représentation interne appris par un modèle d'apprentissage profond, où chaque point correspond à une version compressée — et non directement observable — des données d'entrée. Cet espace est généralement de dimension plus faible que les données brutes : il ne conserve que les caractéristiques essentielles qui décrivent la structure sous-jacente. Sa propriété clé est sémantique : les données qui se ressemblent y sont positionnées proches les unes des autres. Dans un auto-encodeur, un encodeur compresse l'entrée dans l'espace latent, et un décodeur la reconstruit à partir de cette représentation compacte. Les modèles génératifs l'exploitent : dans un VAE (auto-encodeur variationnel), chaque donnée correspond à une distribution de probabilité, ce qui rend l'espace continu et lisse ; dans un GAN, un vecteur de bruit latent sert de point de départ, et le faire varier transforme continûment l'image générée. L'espace latent est étroitement lié à la notion d'embedding : un embedding est une représentation vectorielle où les distances traduisent des similarités, souvent assimilée à un espace latent. Sa dimension est un choix de conception : plus elle est petite, plus la compression est forte.
💬 En termes simples
C'est comme une carte mentale des idées : au lieu des données brutes, on garde une « carte » compacte où les concepts proches sont voisins — il suffit de se déplacer un peu pour passer d'une idée à une idée semblable.
🎯 Exemple concret
Un auto-encodeur entraîné sur des visages apprend un espace latent où une direction correspond à « sourire » : en déplaçant légèrement le vecteur latent dans cette direction, le visage reconstruit se met à sourire, sans qu'on ait jamais étiqueté explicitement le sourire.
💡 Le saviez-vous ?
Dans un espace latent bien structuré, on peut faire de l'« arithmétique » sur les concepts : des chercheurs ont montré qu'on peut additionner et soustraire des attributs (genre, lunettes, âge) en manipulant directement les vecteurs latents.
❓ Questions fréquentes
Quelle différence entre espace latent et embedding ?
Les deux désignent des représentations vectorielles où la proximité traduit la similarité ; « latent » insiste sur des variables cachées d'un modèle génératif, « embedding » sur une représentation où les distances capturent les relations. En pratique, on les emploie souvent de façon interchangeable.
Pourquoi compresser les données dans un espace latent ?
Pour ne garder que les caractéristiques essentielles : cela réduit la dimension, révèle la structure sous-jacente, et permet de générer, comparer ou interpoler des données efficacement.
Reçois chaque semaine le meilleur de l'actualité IA, directement dans ta boîte.
Pas de pourriel, désinscription en 1 clic.
✉️
Restez informé
Recevez nos sélections d'outils et articles directement dans votre boîte courriel.
🔐 Connexion rapide
Entrez votre courriel pour recevoir un code à 6 chiffres.
Pas besoin de mot de passe ni d'inscription. Entrez votre courriel, recevez un code par courriel, et c'est tout !
✓
Paramètres de confidentialité
Nous utilisons des témoins (cookies) pour assurer le bon fonctionnement du site, analyser le trafic et personnaliser le contenu. Vous pouvez gérer vos préférences ci-dessous.
Politique de confidentialité